- دسته بندی کالاها
- شبکه سازان
- سوئیچ شبکه
- روتر میکروتیک
- تجهیزات فیبرنوری
- مودم فیبر نوری
- بلاگ
- تماس با ما
- 021-68215

در مسیریابی کلاسیک، معمولاً با یک شبکه نسبتاً پایدار و با مرزهای مشخص طرف بودیم؛ مثل شبکه یک سازمان (Enterprise) یا یک دیتاسنتر با توپولوژی کنترلشده، لینکهای اختصاصی و الگوهای ترافیکی تا حد زیادی قابل پیشبینی. در چنین محیطی، پروتکلهای مسیریابی عمدتاً با فرض «ثبات نسبی» طراحی و تنظیم میشدند: هزینه لینکها معلوم است، نقاط شکست محدودند، تغییرات بهصورت برنامهریزیشده انجام میشود و اگر هم مشکلی رخ دهد، معمولاً در محدوده همان دامنه شبکه قابل مدیریت است.
اما در Cloud‑Edge، قضیه شبیه رانندگی در شهری است که هر لحظه نقشهاش کمی عوض میشود. شما با ترکیبی از شبکههای اپراتوری، اینترنت عمومی، دیتاسنترهای ابری، نقاط حضور (PoP)، گرههای لبه، و حتی لینکهای بیسیم (مثل 4G/5G و Wi‑Fi) روبهرو هستید. اینجا «بهینه» بودن دیگر یک عدد ثابت نیست؛ وابسته به زمان، مکان، نوع سرویس، وضعیت ازدحام، و حتی محل اجرای برنامه است. مسیری که صبح بهترین انتخاب بوده، عصر ممکن است بهخاطر افزایش ترافیک، تغییر مسیرهای بیناپراتوری، یا جابهجایی کاربر به یک منطقه دیگر، به انتخاب نامناسبی تبدیل شود.
نکته مهمتر این است که در Cloud‑Edge مقصد سرویس همیشه یک نقطه ثابت نیست. ممکن است همان سرویس امروز روی یک Edge نزدیک کاربر اجرا شود و فردا بهدلیل سیاستهای ظرفیت یا هزینه، به یک منطقه ابری دیگر منتقل شود. بنابراین مسیریابی باید «آگاه از سرویس و زمینه» باشد؛ یعنی صرفاً به کوتاهترین مسیر اکتفا نکند و بتواند معیارهایی مثل تأخیر، جیتر، نرخ از دسترفت، هزینه خروجی ابر (Egress) و سیاستهای امنیتی را هم در تصمیمگیری دخالت دهد. به همین دلیل، در این فضا معمولاً با ترکیب فناوریها مواجهیم: از BGP برای بیندامنه تا SD‑WAN برای سیاستگذاری، از Segment Routing برای مهندسی ترافیک تا Telemetry برای تصمیمگیری بر پایه دادههای لحظهای.
از نگاه عملیاتی هم تفاوت چشمگیر است: در مسیریابی کلاسیک، عیبیابی اغلب داخل یک شبکه و با ابزارهای شناختهشده انجام میشد؛ اما در Cloud‑Edge، بخشی از مسیر ممکن است خارج از کنترل مستقیم شما باشد (مثلاً اینترنت عمومی یا شبکه اپراتور). پس طراحی باید از ابتدا تابآور باشد: مسیر جایگزین، Failover سریع، مشاهدهپذیری (Observability) دقیق، و سیاستهای روشن برای کیفیت سرویس.
در نهایت، اگر قرار باشد زیرساخت Cloud‑Edge را پیادهسازی کنید، انتخاب تجهیزات و معماری اهمیت پیدا میکند؛ چون بسیاری از این قابلیتها به توان پردازشی، پشتیبانی از پروتکلها و امکانات مانیتورینگ وابستهاند موضوعی که هنگام خرید روتر شبکه هم باید دقیق بررسی شود تا دستگاه صرفاً «مسیر بدهد» نه اینکه خودش به گلوگاه تبدیل شود.
وقتی صحبت از بازی ابری، تماس ویدئویی، AR/VR یا کنترل صنعتی میشود، چند میلیثانیه واقعاً اهمیت دارد. دلیلش هم ساده است: این نوع برنامهها «تعاملمحور» هستند؛ یعنی کاربر یا دستگاه منتظر پاسخ فوری میماند و اگر پاسخ دیر برسد، تجربه بهسرعت افت میکند. در بازی ابری، تأخیر باعث میشود فرمان شما دیرتر اجرا شود و حس کنترل از دست برود. در تماس ویدئویی، حتی اگر کیفیت تصویر بالا باشد، تأخیر زیاد باعث میشود مکالمه طبیعی نباشد، وسط حرف همدیگر بیفتید و ارتباط از حالت روان خارج شود. در AR/VR هم تأخیر میتواند به ناهماهنگی تصویر و حرکت سر منجر شود و کل حس واقعگرایی را خراب کند. در کنترل صنعتی، موضوع از تجربه کاربری هم فراتر میرود؛ تأخیر میتواند روی دقت، ایمنی و پایداری فرآیند اثر بگذارد و گاهی حتی ریسک عملیاتی ایجاد کند.
این برنامهها مثل یک ارکسترند؛ اگر یکی از سازها یک ضرب عقب بیفتد، کل قطعه بههم میریزد. نکته اینجاست که مشکل فقط «دیر رسیدن» نیست؛ «نوسان» هم به همان اندازه مخرب است. ممکن است یک لحظه همهچیز خوب باشد و لحظه بعد، به دلیل تغییر مسیر یا ازدحام، تأخیر بالا برود و دوباره پایین بیاید. این نوسان باعث میشود سیستمهای جبرانسازی هم نتوانند درست عمل کنند؛ بافرها بیش از حد پر یا خالی میشوند و کیفیت سرویس پیوستگی خود را از دست میدهد.
بنابراین، در چنین سناریوهایی مسیریابی در Cloud-Edge باید «حساس به تأخیر و نوسان» باشد، نه صرفاً حساس به پهنای باند. یعنی تصمیم مسیر باید طوری گرفته شود که مسیر انتخابی فقط ظرفیت کافی نداشته باشد، بلکه پایدار، قابل پیشبینی و کمنوسان هم باشد. از طرفی، این حساسیت باید در طول زمان حفظ شود؛ چون مسیر مناسبِ همین لحظه ممکن است چند دقیقه بعد، دیگر مناسب نباشد. پس مسیریابی باید بتواند تغییرات شبکه را سریع تشخیص دهد، بهموقع واکنش نشان دهد و بدون ایجاد اختلال محسوس، مسیر را به گزینه بهتر منتقل کند؛ دقیقاً مثل رهبر ارکستر که اگر یکی از نوازندهها از ریتم خارج شود، کل گروه را هماهنگ میکند تا اجرای قطعه خراب نشود.
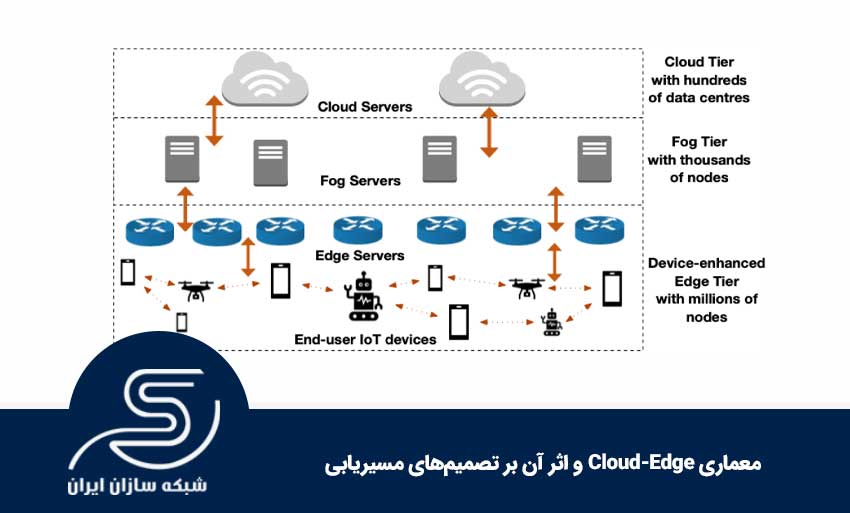
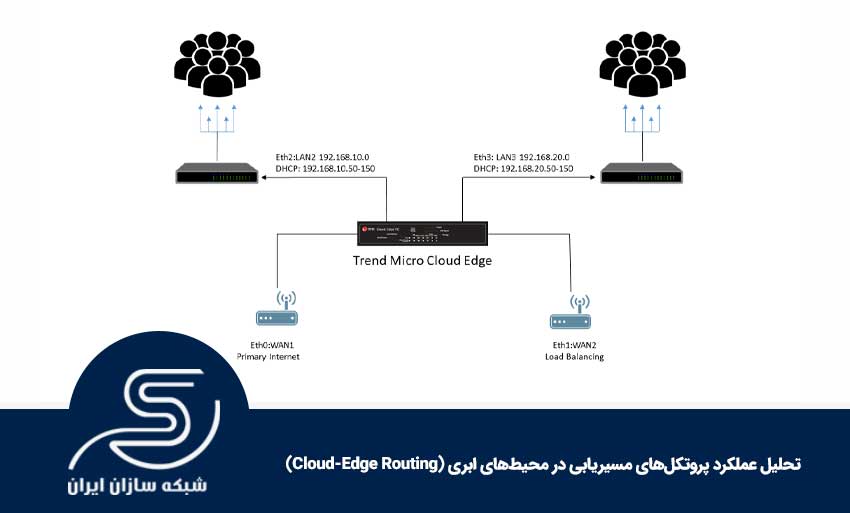
برای تحلیل عملکرد پروتکلهای مسیریابی، قبل از هر چیز باید «صحنه» را درست ببینیم: داده دقیقاً از کجا وارد میشود، در چه نقاطی پردازش یا مسیردهی میگیرد، و در نهایت به کجا میرسد؟ مهمتر از آن، چه موجودیتی مسیر را انتخاب میکند: یک پروتکل توزیعشده، یک کنترلر متمرکز، یا ترکیبی از هر دو؟ وقتی این تصویر شفاف شود، تازه میتوان فهمید چرا یک تصمیم مسیریابی در یک سناریو عالی است و در سناریوی دیگر مشکلساز میشود.
این سه مفهوم در عمل به شکل یک زنجیره پیوسته عمل میکنند، نه سه جزیره جدا. همین پیوستگی باعث میشود مسیریابی بهجای یک مسئله ساده «انتخاب کوتاهترین مسیر»، تبدیل به مسئلهای چندبعدی شود: مسیر باید با لایه پردازشی هماهنگ باشد.
وقتی سرویس در Edge اجرا میشود، هدف مسیریابی معمولاً این است که داده با کمترین تأخیر به نزدیکترین گره لبه برسد؛ یعنی مسیرهایی که رفتوبرگشت کوتاهتری دارند و نوسان کمتری ایجاد میکنند، اولویت پیدا میکنند. اما اگر همان سرویس بهخصوص برای تحلیل سنگین، آموزش مدل، یا ذخیرهسازی بلندمدت به Cloud منتقل شود، مسیر طولانیتر میشود و وابستگی به کیفیت شبکه بینراهی افزایش مییابد. در این حالت، حتی اگر پهنای باند کافی باشد، یک گلوگاه کوچک یا ازدحام مقطعی میتواند اثر قابلتوجهی روی کیفیت سرویس بگذارد.
نکته مهم این است که در محیطهای مدرن، «محل استقرار سرویس» ثابت نیست. ممکن است سرویس بهصورت پویا بین چند Edge و چند ناحیه Cloud جابهجا شود (بهخاطر بار، هزینه، یا سیاستهای دسترسپذیری). بنابراین مسیریابی باید بتواند با این جابهجاییها هماهنگ شود؛ یعنی نهفقط مقصد IP را بشناسد، بلکه بداند مقصد واقعی سرویس در این لحظه کجاست و بهترین مسیر برای رسیدن به آن کدام است. در غیر این صورت، شبکه شبیه این میشود که شما آدرس را دارید، اما مقصد هر چند ساعت یکبار خانهاش را عوض میکند و شما همچنان به نشانی قبلی میروید.
از منظر عملیاتی هم این موضوع روی انتخاب تجهیزات اثر میگذارد؛ چون وقتی تصمیم دارید بخشی از مسیر را در Edge مدیریت کنید، قابلیتهای مسیریابی، پایش و کنترل ترافیک در لبه اهمیت پیدا میکند و طبیعی است که هنگام برنامهریزی برای پیادهسازی، موضوعاتی مثل خرید روتر میکروتیک هم در کنار ملاحظات فنی مطرح شود بهخصوص وقتی نیاز به راهکارهای مقرونبهصرفه برای سناریوهای لبه و شعب وجود دارد.
در بسیاری از معماریهای جدید، تصمیمگیری (Control Plane) ممکن است در یک کنترلر SDN، سامانه مدیریت سیاست، یا حتی در ترکیبی از کنترلرهای متمرکز و توزیعشده انجام شود؛ اما عبور واقعی ترافیک (Data Plane) در گرههای لبه، روترها، سوئیچها و شبکههای مختلف اتفاق میافتد. این جداسازی یک مزیت بزرگ دارد: کنترل میتواند «دید سراسری» داشته باشد و سیاستهای یکپارچه اعمال کند. اما همزمان یک حساسیت هم ایجاد میشود: هرچه فاصله بین کنترل و داده بیشتر شود، واکنش به تغییرات کندتر میشود.
به زبان ساده، اگر Data Plane در Edge با یک رخداد سریع مواجه شود (مثلاً افت کیفیت لینک، ازدحام ناگهانی یا قطعی کوتاه)، اما Control Plane دیر متوجه شود یا دیر تصمیم جدید را اعمال کند، نتیجه میتواند ناپایداری یا افت کیفیت باشد. اینجا دو مفهوم کلیدی مطرح میشود:
در Cloud-Edge، بهترین طراحی معمولاً طراحیای است که هم سرعت واکنش محلی را حفظ کند (مثلاً تصمیمهای سریع در لبه)، و هم هماهنگی سیاستمحور سراسری را از دست ندهد (مثلاً کنترل مرکزی برای اهداف کلان). دقیقاً مثل یک سازمان بزرگ: اگر همه تصمیمها فقط از مرکز صادر شود، کارها کند میشود؛ اگر هم هر شعبه مستقل عمل کند، نظم از بین میرود. هنر معماری Cloud-Edge این است که تعادل درست بین این دو برقرار شود.
تحلیل عملکرد بدون معیار، مثل قضاوت درباره کیفیت یک خودرو بدون نگاه به مصرف سوخت، شتاب و ایمنی است. در Cloud-Edge Routing اگر معیارها دقیق تعریف نشوند، ممکن است یک راهکار روی کاغذ «بهینه» به نظر برسد اما در عمل، تجربه کاربر را خراب کند یا هزینه عملیاتی را بالا ببرد. نکته مهم این است که در Cloud-Edge معمولاً با چند هدف همزمان مواجه هستیم: کاهش تأخیر، حفظ پایداری، کنترل هزینه، و مقیاسپذیری. بنابراین ارزیابی هم باید چندبعدی باشد، نه تکمعیاره.
در ارزیابی حرفهای، معمولاً علاوه بر میانگین تأخیر، شاخصهایی مثل صدک ۹۵/۹۹ (P95/P99) هم بررسی میشود، چون کاربران معمولاً افت کیفیت را در همان لحظات بد تجربه میکنند، نه در میانگینها.
اگر مسیر «سریع» باشد ولی بستهها را گم کند، سرویس عملاً بیکیفیت است. در Edge، بهخصوص روی لینکهای بیسیم، Loss میتواند تعیینکننده باشد. از دسترفت بستهها دو اثر زنجیرهای دارد:
در تحلیل Cloud-Edge باید مشخص شود Loss از کجا میآید: ازدحام؟ کیفیت لینک؟ تنظیمات صف و بافر؟ یا مسیرهای ناپایدار؟ پاسخ هر کدام متفاوت است و روی تصمیمهای مسیریابی اثر میگذارد.
در برخی سناریوها (مثل انتقال مدلهای ML، همگامسازی داده، بکآپ یا توزیع محتوا)، توان عبوری مهمترین معیار است. اما در Cloud-Edge، Throughput فقط به ظرفیت لینک وابسته نیست؛ مسیر انتخابی، میزان ازدحام، رفتار پروتکلها و حتی سربار تونلینگ/Overlay میتواند Throughput واقعی را کم کند.
اینجا یک خطای رایج هم وجود دارد: گاهی مسیر کمتأخیر انتخاب میشود، اما به دلیل ازدحام، Throughput کاهش پیدا میکند و کل کار کندتر از مسیر جایگزینِ کمی دورتر تمام میشود. بنابراین باید بین تأخیر و توان عبوری، تعادل متناسب با نوع سرویس برقرار شود.
مسیریابی نیاز به پیامهای کنترلی دارد: اعلان مسیر، Hello، بهروزرسانی جدولها و موارد مشابه. در Edge با تعداد زیاد گره و تغییرات پیوسته، اگر سربار کنترل زیاد شود، شبکه به جای حمل داده، درگیر «حرف زدن درباره مسیر» میشود. نتیجه میتواند این باشد که:
اینجاست که طراحی سلسلهمراتبی، خلاصهسازی مسیرها، محدود کردن دامنه تغییرات، و انتخاب درست مکانیزمهای اعلان مسیر اهمیت پیدا میکند. همچنین باید توجه داشت که ظرفیت سختافزار و کارایی Control Plane هم وارد بازی میشود؛ برای مثال در شبکههایی که بخشی از زیرساخت بر پایه تجهیزات سازمانی شکل گرفته، توان پردازش مسیرها و ویژگیهای نرمافزاری دستگاههایی مثل روتر سیسکو میتواند در مقیاسپذیری و ثبات مسیریابی اثر مستقیم داشته باشد.
وقتی لینک قطع میشود یا مسیر تغییر میکند، پروتکل چقدر سریع به حالت پایدار جدید میرسد؟ همگرایی کند یعنی کاربران افت کیفیت را حس میکنند. اما فقط سرعت همگرایی مهم نیست؛ «کیفیت همگرایی» هم مهم است. یعنی:
در Cloud-Edge، چون رخدادها (قطع کوتاه، تغییر کیفیت لینک، جابهجایی کاربر) بیشتر است، پایداری مسیر به یک معیار کلیدی تبدیل میشود. بهترین طراحیها معمولاً هم مسیر جایگزین آماده دارند و هم سیاستهای مشخص برای جلوگیری از نوسان بیش از حد، تا شبکه شبیه درِ چرخان نشود که ترافیک را مدام بین مسیرها جابهجا کند.
Cloud-Edge Routing با چند مشکل همزمان روبهروست؛ و دقیقاً همین «همزمانی» کار را سخت میکند. در مسیریابی کلاسیک، معمولاً با یک شبکه نسبتاً پایدار، مرزهای روشن، و چند پروتکل شناختهشده طرف هستیم. اما در Cloud-Edge، مسیرها باید بین چند دامنه (اپراتور، اینترنت عمومی، دیتاسنتر، لبههای پراکنده) تصمیمگیری کنند، آن هم در حالی که کاربران و سرویسها مدام در حال حرکت یا جابهجاییاند. نتیجه این است که مسیریابی صرفاً انتخاب یک مسیر نیست؛ مدیریت پیوستهی «بهترین مسیر در همین لحظه» است.
کاربر موبایل حرکت میکند، سرویس روی کانتینرها جابهجا میشود، لبهها فعال/غیرفعال میشوند. مسیر باید با این تغییرات کنار بیاید؛ وگرنه تصمیمهای دیروز، امروز اشتباهاند.
در Cloud-Edge این پویایی چند شکل مهم دارد:
چالش اصلی اینجاست: مسیریابی باید هم چابک باشد (برای واکنش سریع)، و هم پایدار بماند (تا مدام مسیر عوض نشود و نوسان ایجاد نکند).
در معماریهای جدید، چند مسیر ممکن همزمان وجود دارد. انتخاب بین آنها باید با آگاهی از ازدحام و ظرفیت واقعی باشد. مسیریابی کورکورانه مثل انتخاب سریعترین صف بدون نگاه به اینکه ناگهان یک اتوبوس واردش شده است.
اما در Cloud-Edge، موضوع فقط «وجود چند مسیر» نیست؛ مسئله این است که:
بنابراین چالش این است که مسیریابی باید از «هزینه ثابت» فاصله بگیرد و به سمت معیارهای پویا برود: سنجش تأخیر واقعی، تشخیص ازدحام، یا سیاستهای هوشمند برای توزیع ترافیک. اگر این آگاهی وجود نداشته باشد، شبکه ممکن است همه ترافیک را به یک مسیر محبوب بفرستد و همان مسیر را از پا بیندازد (اثر ازدحام خود-القایی).
همه لینکها مثل هم نیستند: یکی پایدار اما کند، دیگری سریع اما نوسانی. پروتکلها و سیاستها باید این تفاوت را بفهمند و فقط به «هزینه ثابت» بسنده نکنند.
در عمل، ناهمگونی یعنی تفاوت همزمان در چند ویژگی:
نتیجه: مسیریابی در Cloud-Edge باید بتواند لینکها را «طبقهبندی» کند و برای هر نوع ترافیک (بلادرنگ، حجیم، کنترلی) مسیر مناسب را انتخاب کند. حتی تصمیمهای خرید و طراحی شبکه هم تحت تأثیر همین ناهمگونی است؛ چون گاهی بررسیهایی مثل قیمت روتر تی پی لینک در کنار نیازهای فنی مطرح میشود تا مشخص شود برای یک سایت لبه با بار مشخص، چه سطحی از تجهیزات و چه نوع لینک اقتصادیتر و پایدارتر است.
در Edge، گاهی زیرساخت مشترک بین چند سرویس/سازمان است. مسیریابی باید هم جداسازی ترافیک را رعایت کند، هم در برابر مسیرهای مخرب یا اشتباه مقاوم باشد.
چالشهای امنیتی Cloud-Edge معمولاً چند لایهاند:
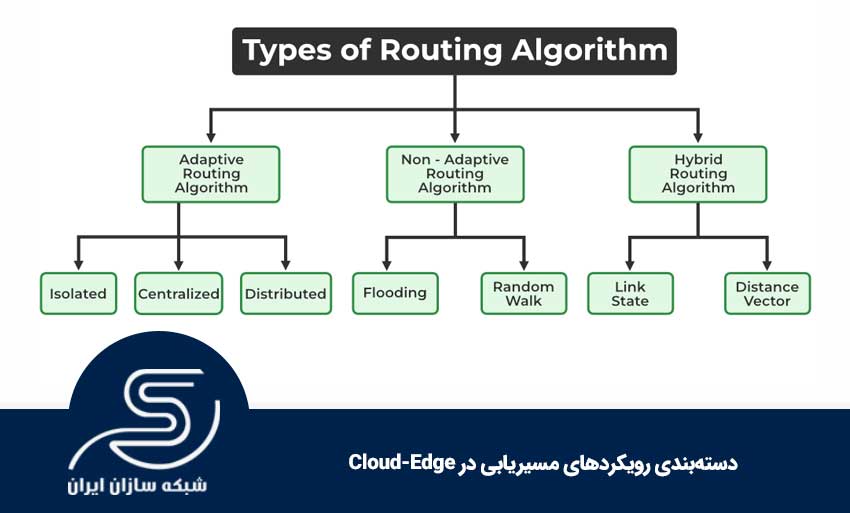
برای تحلیل عملکرد، بهتر است رویکردها را دستهبندی کنیم؛ چون «یک پروتکل» بهتنهایی همه نیازها را پوشش نمیدهد. در Cloud-Edge معمولاً با یک پشته ترکیبی روبهرو هستیم: بخشی از تصمیمگیریها در سطح بیندامنه (مثلاً بین چند شبکه/ارائهدهنده)، بخشی درون دیتاسنتر/ابر، و بخشی نزدیک کاربر در Edge انجام میشود. به همین دلیل، رویکردهای مسیریابی بیشتر از آنکه «فقط انتخاب مسیر» باشند، تبدیل به ترکیبی از سیاست، تضمین کیفیت، آگاهی از سرویس، مدیریت هزینه و حتی پیشبینی شدهاند.
در ادامه، دستههای اصلی را با نگاه کاربردیتر بسط میدهیم.
اینجا هدف فقط کوتاهی مسیر نیست؛ سیاست میگوید ترافیک مالی از مسیر خاصی برود، ترافیک مهم از لینک امنتر عبور کند، یا ترافیک ویدئویی به نزدیکترین Edge هدایت شود.
در Cloud-Edge، سیاستها معمولاً از جنس «قیود» هستند، نه صرفاً ترجیحات. یعنی ممکن است بگوییم:
چالش عملکردی در PBR این است که اگر سیاستها زیاد و جزئی شوند، هم پیچیدگی عملیاتی بالا میرود و هم خطر ناسازگاری سیاستها (Policy Conflict) افزایش مییابد. بنابراین در ارزیابی عملکرد باید سنجید که سیاستمحوری چه اثری روی مقیاسپذیری، زمان همگرایی و احتمال خطا دارد.
در محیطهای ابری، SLA حرف اول را میزند. مسیریابی باید بتواند تا حد امکان تضمین دهد که تأخیر/ازدسترفت از حدی بالاتر نرود، یا دستکم وقتی نقض شد، سریع مسیر جایگزین پیدا کند.
اینجا دو رویکرد رایج دیده میشود:
نکته مهم: SLA فقط «میانگین» نیست. بسیاری از سرویسها با P95/P99 تعریف میشوند. یعنی مسیریابی باید طوری طراحی شود که دُم توزیع (لحظات بد) کنترل شود، نه فقط میانگین روزانه.
به جای اینکه فقط «IP مقصد» ملاک باشد، سرویس و نوع ترافیک هم وارد تصمیم میشود. مثلاً ترافیک APIهای حساس از مسیر پایدارتر، و ترافیک دانلود از مسیر ارزانتر عبور کند.
در Cloud-Edge، Service-Aware بودن معمولاً یعنی شبکه بتواند بین اینها تمایز بگذارد:
این رویکرد کمک میکند بهجای اینکه همه ترافیکها یکسان رفتار شوند، «هر سرویس» مسیر مناسب خودش را بگیرد. اما چالش ارزیابی عملکرد این است که Service-Aware Routing معمولاً نیازمند طبقهبندی ترافیک و گاهی وابسته به دادههای لایه بالاتر است؛ این یعنی سربار پردازشی، پیچیدگی سیاستها و احتمال خطا در شناسایی (Misclassification) باید در تحلیل لحاظ شود.
در Edge، ممکن است برخی گرهها محدودیت انرژی داشته باشند یا هزینه خروجی ابر (Egress Cost) بالا باشد. مسیر «ارزانتر» گاهی از مسیر «کوتاهتر» منطقیتر است.
دو منبع هزینه معمولاً تعیینکنندهاند:
در تحلیل عملکرد این رویکرد، باید «بهینگی» را صرفاً به تأخیر ترجمه نکرد. گاهی یک مسیر با چند میلیثانیه تأخیر بیشتر، اگر هزینه را بهطور معنادار کاهش دهد، از منظر کسبوکار بهتر است. اینجاست که معیارهای عملکرد با معیارهای اقتصادی گره میخورند.
وقتی شبکه پیچیده و پویاست، مدلها میتوانند ازدحام را پیشبینی کنند یا بهترین مسیر را بر اساس الگوهای گذشته پیشنهاد دهند. البته شرطش داده خوب و طراحی محافظهکارانه است؛ چون تصمیم اشتباه میتواند گسترده اثر بگذارد.
در عمل، ML-Driven Routing معمولاً یکی از این نقشها را بازی میکند:
چالشهای کلیدیاش هم روشن است:
این دستهها فقط تعریف تئوری نیستند؛ در پروژههای واقعی معمولاً همپوشانی دارند. مثلاً ممکن است یک شبکه همزمان:
به همین دلیل، از همان مراحل طراحی و راه اندازی دیتاسنتر باید مشخص شود اولویت سازمان چیست: کمترین تأخیر؟ بیشترین پایداری؟ کمترین هزینه؟ یا ترکیبی از همه؟ چون پاسخ این سؤال تعیین میکند کدام رویکرد غالب شود و ارزیابی عملکرد بر چه معیارهایی متمرکز باشد.
حالا برویم سراغ بازیگران اصلی. نکته این است که در Cloud-Edge معمولاً با «ترکیب» پروتکلها سروکار داریم، نه یک گزینه واحد.
BGP ستون فقرات مسیریابی بیندامنه است. مزیتش مقیاسپذیری و سازگاری گسترده است، اما برای نیازهای Edge (واکنش سریع به تغییر، آگاهی از تأخیر) ذاتاً طراحی نشده. در تحلیل عملکرد BGP در Cloud-Edge معمولاً این موارد سنجیده میشود:
در شبکههای داخلی (Intra-domain)، OSPF/IS-IS بهخاطر همگرایی سریعتر و کنترل بهتر، محبوباند. اما در محیطهای بسیار بزرگ و پویا، سربار و پیچیدگی طراحی Areaها و LSAها مطرح میشود. تحلیل عملکرد اینجا معمولاً شامل:
Segment Routing مثل این است که به بستهها یک برنامه سفر بدهیم: «اول برو اینجا، بعد برو آنجا». با SR میتوان مهندسی ترافیک دقیقتری داشت و مسیرها را آگاهانه کنترل کرد. در Edge، SRv6 میتواند انعطاف خوبی بدهد، اما نیازمند آمادگی زیرساخت و مهارت عملیاتی است. معیارهای ارزیابی:
SDN وعده میدهد «کنترل» را متمرکز و قابل برنامهریزی کند. در Cloud-Edge، مزیت SDN دید سراسری و تصمیمگیری مبتنی بر دادههای لحظهای است. اما اگر کنترلر دور باشد یا نقطه شکست واحد ایجاد شود، ریسک بالا میرود. در تحلیل عملکرد SDN بررسی میشود:
در ابر و دیتاسنتر، Overlayها رایجاند. آنها جداسازی منطقی عالی میدهند، اما میتوانند مسیر را پیچیدهتر و عیبیابی را سختتر کنند. در Edge نیز اگر Overlay روی اینترنت عمومی سوار شود، تحلیل MTU، Fragmentation و سربار Encapsulation حیاتی میشود.
اگر هدف شما «تحلیل علمی» است، باید روشمند جلو بروید؛ وگرنه نتایج بیشتر شبیه حدس میشود.
قبل از هر اندازهگیری، مشخص کنید چه نوع ترافیکی دارید و چه چیزی برایتان مهم است.
برای شروع، شبیهسازی کمک میکند بدون هزینه سختافزاری، الگوها را ببینید. امولیشن هم برای نزدیک شدن به واقعیت (مثلاً با Mininet) مفید است.
در محیط واقعی، Telemetry (مثل streaming telemetry)، NetFlow/IPFIX، و Tracing سرویسها برای فهم مسیر واقعی و گلوگاهها ضروری است. بسیاری از مشکلات Cloud-Edge اصلاً در نمودارهای کلی دیده نمیشوند؛ باید ریز شوید.
بهجای ادعاهای کلی، چند سناریوی رایج را مرور کنیم تا تصویر شفاف شود.
اینجا معمولاً ترکیب سیاستمحور + آگاهی از تأخیر بهترین نتیجه را میدهد. پروتکلهای صرفاً لینک-استیت، بدون ورودی تأخیر لحظهای، ممکن است مسیر «از نظر توپولوژی کوتاه» اما «از نظر تجربه کاربر بد» انتخاب کنند. استفاده از Telemetry و مسیرهای از پیش مهندسیشده (مثلاً با SR) میتواند کیفیت را پایدارتر کند.
در این حالت، Throughput و هزینه مهم میشود. ممکن است مسیر کمی طولانیتر، اما ارزانتر و پایدارتر انتخاب شود. اینجا سیاستها و زمانبندی (مثلاً انتقال در ساعات کمترافیک) اثر زیادی دارد.
این سناریو آزمون واقعی «همگرایی» است. پروتکلی که در حالت عادی عالی است، ممکن است در هنگام Failover افت شدید ایجاد کند. در Cloud-Edge، بهترین طراحی معمولاً ترکیبی از:
است.
Overlayها و سیاستها کمک میکنند هر مستأجر مسیر و کیفیت خودش را داشته باشد. اما سربار و پیچیدگی افزایش مییابد. در تحلیل عملکرد باید سنجید آیا جداسازی با افت قابل توجه latency/MTU همراه شده یا خیر.
در پیادهسازی واقعی، «راهحل عالی روی کاغذ» کافی نیست؛ باید عملیاتی، قابل نگهداری و قابل عیبیابی باشد.
هر فناوری جدید جذاب است، اما ترکیب بیحساب، شبکه را شکننده میکند. معماری را طوری بچینید که تیم عملیات بتواند در ساعت ۳ صبح هم عیبیابی کند.
در بسیاری از سازمانها، یک ترکیب عملی و مؤثر این است:
به جای اینکه منتظر شوید لینک قطع شود تا شبکه فکر کند، مسیر جایگزین را از قبل آماده کنید. همچنین مراقب باشید Failover بیش از حد حساس نباشد که باعث نوسان دائمی شود.
Edge نزدیک کاربر است و بیشتر در معرض تهدید. مسیریابی و دسترسی باید بر اساس «عدم اعتماد پیشفرض» طراحی شود: احراز هویت، حداقل دسترسی، و پایش مداوم.
تحلیل عملکرد پروتکلهای مسیریابی در Cloud-Edge Routing یعنی نگاه همزمان به معماری، معیارها، پویایی شبکه و نیاز سرویسها؛ زیرا در این الگو، مسیر داده صرفاً یک انتخاب فنی در سطح شبکه نیست، بلکه مستقیماً با محل اجرای پردازش (Cloud، Edge یا Fog)، الگوی جابهجایی کاربران و دستگاهها، و سطح انتظار از کیفیت سرویس گره خورده است. به همین دلیل، ارزیابی «عملکرد» باید چندبعدی انجام شود و علاوه بر شاخصهای کلاسیک، اثر تصمیمهای مسیریابی بر تجربه کاربر نهایی، پایداری سرویس و هزینه عملیاتی نیز سنجیده شود.
در این محیط، معمولاً یک پروتکل بهتنهایی پاسخگو نیست؛ چون همزمان با چند واقعیت روبهرو هستیم: ناهمگونی لینکها و مسیرها، تغییرپذیری بار ترافیکی، رخدادهای لحظهای مانند ازدحام یا جابهجایی نقطه اتصال، و نیاز به اعمال سیاستهای متفاوت برای سرویسهای مختلف. بنابراین بهترین نتیجه از ترکیب رویکردها به دست میآید؛ از جمله سیاستمحور بودن برای همراستاسازی شبکه با الزامات کسبوکار، مهندسی ترافیک برای توزیع هوشمند بار و جلوگیری از ایجاد گلوگاه، پایش دقیق برای تشخیص سریع افت کیفیت و اصلاح مسیر، و طراحی تابآور برای حفظ دسترسپذیری در برابر خرابیها و نوسانات.
اگر هدف از ابتدا درست تعریف شود مثلاً کاهش تأخیر انتها به انتها، کنترل جیتر برای سرویسهای بلادرنگ، افزایش پایداری و سرعت همگرایی، یا بهینهسازی هزینه و مصرف منابع انتخاب فناوری و پروتکل نیز منطقی، قابل دفاع و قابل اندازهگیری خواهد بود. در عمل، موفقترین طراحیها آنهایی هستند که بین «کارایی شبکه» و «نیاز واقعی سرویس» تعادل برقرار میکنند، دامنه تصمیمگیری مسیریابی را با واقعیتهای عملیاتی شبکه هماهنگ میسازند، و با رویکردی دادهمحور (Metrics-Driven) امکان بهبود مستمر را فراهم میکنند.
1-مهمترین معیار برای ارزیابی مسیریابی در Cloud-Edge چیست؟
بسته به سرویس است، اما در بسیاری از کاربردهای Edge، تأخیر و جیتر در کنار پایداری مسیر مهمترین معیارها هستند.
2-آیا BGP برای Cloud-Edge کافی است؟
برای بیندامنه و چندابر، BGP ضروری است، اما بهتنهایی برای نیازهای Edge (واکنش سریع، QoS لحظهای) کافی نیست و معمولاً با SD-WAN، Telemetry یا SR تکمیل میشود.
3- SDN همیشه عملکرد را بهتر میکند؟
خیر. SDN دید و کنترل بهتری میدهد، اما اگر طراحی کنترلر، مقیاسپذیری و تابآوری درست نباشد، میتواند نقطه ضعف ایجاد کند.
4-Overlayها چه ریسکی برای عملکرد دارند؟
مهمترین ریسکها سربار Encapsulation، مشکلات MTU/Fragmentation، و پیچیدگی عیبیابی است. اگر مدیریت نشوند، روی latency و loss اثر میگذارند.
5-برای شروع تحلیل عملکرد، از کجا آغاز کنیم؟
از تعریف دقیق سناریو و معیارها. سپس با شبیهسازی/امولیشن شروع کنید و در نهایت با Telemetry و دادههای واقعی، نتایج را اعتبارسنجی کنید.
 قیمت کالا بدون احتساب ارزش افزوده (۱۰درصد) می باشد و در صورت نیاز به فاکتور رسمی ارزش افزوده لحاظ میگردد
قیمت کالا بدون احتساب ارزش افزوده (۱۰درصد) می باشد و در صورت نیاز به فاکتور رسمی ارزش افزوده لحاظ میگردد پشتیبانی آنلاین
پشتیبانی آنلاین ضمانت اصلی بودن کالا
ضمانت اصلی بودن کالا تحویل اکسپرس شبکه سازان
تحویل اکسپرس شبکه سازان